SportPulse.today
SportPulse.today
Section titled “SportPulse.today”What this project is
Section titled “What this project is”SportPulse.today is a strong case for studying real-time data product thinking.
The value here does not come from a flashy interface.
It comes from something more important for engineering:
- collect information
- process it quickly
- organize the response
- expose it clearly
This kind of project teaches a lot because there is a real tension between:
- constant updates
- product simplicity
- processing cost
- architectural clarity
What problem it solves
Section titled “What problem it solves”People consuming sports content usually want:
- fast context
- continuous updates
- objective reading
- immediate response
Projects like this need to transform volume and speed into something usable.
In other words:
having data is not enough.
You need to:
- search
- filter
- organize
- deliver
without turning the whole thing into chaos.
Why this case is good for developers
Section titled “Why this case is good for developers”This is the kind of product that forces you to think about applied engineering for real.
Not pretty abstraction.
Actual problems.
When studying the case, it is worth paying attention to topics like:
- data ingestion
- response normalization
- perceived latency
- endpoint modeling
- clear separation between layers
- tolerance to external failures
What to study here as a developer
Section titled “What to study here as a developer”1. Throughput-oriented backend thinking
Section titled “1. Throughput-oriented backend thinking”When the product depends on frequent updates, the backend needs to stay well organized.
That pushes you to think about:
- processing cost
- overhead per request
- responsibility of each module
- pipeline organization
2. External-source integration
Section titled “2. External-source integration”This kind of solution usually needs to talk to services, feeds, or external providers.
And that brings classic pain:
- timeouts
- inconsistent responses
- rate limits
- outages
- different formats
Projects like this are a great reminder that integration is not just “do a fetch.”
3. Data modeling for fast consumption
Section titled “3. Data modeling for fast consumption”Even when a lot of data exists, delivery still needs to feel simple.
That requires:
- clean response structure
- well-chosen fields
- useful ordering
- predictable filtering
4. Performance with responsibility
Section titled “4. Performance with responsibility”When C++ is part of the core technical direction, the performance conversation becomes even more relevant.
But good performance is not only “runs fast.”
It is running fast with:
- organization
- predictability
- maintainability
Architecture: what is worth observing
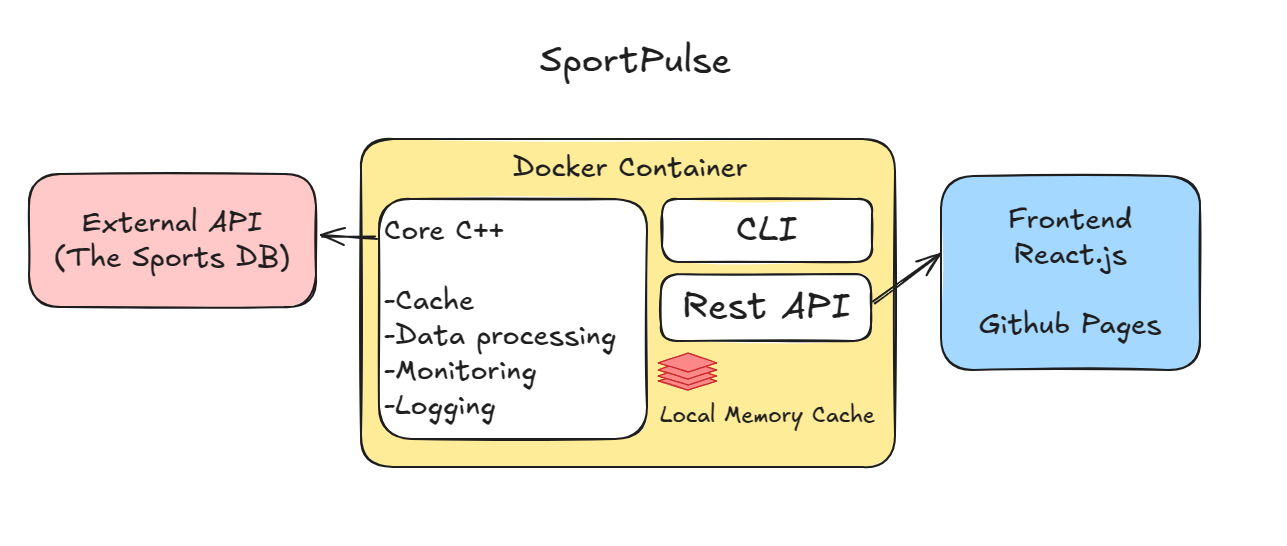
Section titled “Architecture: what is worth observing”A useful way to read this project is to think in layers:
Data input | vNormalization / processing | vBusiness rules | vAPI or interface exposureThat mental split helps a lot because it stops the whole system from becoming one giant blob.
Questions I would ask while studying this case
Section titled “Questions I would ask while studying this case”- Where does the data come from?
- Where is the data cleaned?
- Where is the data transformed?
- Where does the product decide what to surface first?
- Where are the most sensitive latency points?
- What happens when an external source fails?
Even without the full codebase in front of you, those questions already upgrade the quality of your study.
Data structures this kind of project often needs
Section titled “Data structures this kind of project often needs”Projects with search, aggregation, and update pressure usually depend on strong modeling choices.
Examples of structures that make sense to study with this case:
vector/ array for ordered sequencesunordered_map/ map for key-based lookupsetfor deduplicationpriority queue/ heap for ranking or prioritization
The point is not to guess the exact implementation.
The point is to understand:
which operation dominates the problem?
Algorithms and patterns that fit this project
Section titled “Algorithms and patterns that fit this project”If you want to use this case as a springboard for study, focus on:
- sorting
- filtering
- searching
- aggregation
- ranking
- caching
- incremental updates
This connects extremely well with:
Real trade-offs a project like this tends to have
Section titled “Real trade-offs a project like this tends to have”Richer response versus faster response
Section titled “Richer response versus faster response”The more data you aggregate and process, the more context you can expose.
But that can cost:
- higher latency
- more complexity
- more failure points
Continuous updates versus operational simplicity
Section titled “Continuous updates versus operational simplicity”Real-time products look great on the surface.
In practice, they demand:
- monitoring
- retry strategy
- observability
- external dependency care
Performance versus maintainability
Section titled “Performance versus maintainability”Choosing a performance-oriented stack increases technical potential.
But it also demands stronger project discipline.
What I would observe in the product as a technical user
Section titled “What I would observe in the product as a technical user”- clarity of the value proposition
- perceived speed
- consistency of information
- readability of the content
- predictability of navigation
Because a good backend is not there only to look impressive on an architecture diagram.
It exists so the product feels trustworthy to the person using it.
How to turn this case into active study
Section titled “How to turn this case into active study”You can get excellent exercises from it:
- design a minimum architecture for sports aggregation
- model one search endpoint and one listing endpoint
- think through a cache strategy
- model a ranking or filtering structure
- list possible integration failures and how to handle them
This kind of exercise puts you into engineer mode.
Study checklist
Section titled “Study checklist”- Can you explain the product data flow?
- Can you describe where performance matters most?
- Can you think through a clear API contract?
- Can you list integration risks?
- Can you justify which data structures would make sense?
If yes, there is already a lot of technical value to extract from this case.
Next actions
Section titled “Next actions”- Revisit Data Structures with search, indexing, and aggregation in mind.
- Strengthen Algorithms with a focus on sorting, search, and cost.
- Read What is SRE? to connect backend work with reliability.
- Live project: sportpulse.today
- Back to Projects