Como montar um RAG local com PDFs usando Ollama, LangChain, Chroma e Gradio

Ollama + LangChain + Chroma
Uma IA privada para conversar com seus PDFs, rodando na sua máquina e sem custo por uso
Se você quer sair do chat genérico e construir algo com cara de aplicação real de IA, esse projeto é um ótimo ponto de entrada. Em menos de 30 minutos dá para montar um RAG local que lê PDFs, indexa o conteúdo e responde perguntas com contexto de verdade.
Tudo aqui roda 100% local, sem API externa, sem custo por token e com privacidade total.
Em menos de meia hora você vai ter uma IA que lê ebook, edital, artigo técnico, manual ou
qualquer coleção de PDFs e responde perguntas como se fosse um assistente focado naquele material.
Esse tipo de arquitetura se chama RAG (Retrieval-Augmented Generation) e continua sendo uma das
bases mais úteis para aplicações reais de IA em 2026. O melhor é que, além de montar algo que já
serve para portfólio, você ainda entende os fundamentos no caminho.
Por que esse projeto vale tanto a pena
Seção intitulada “Por que esse projeto vale tanto a pena”- RAG é uma das arquiteturas mais presentes em produto de IA de verdade, não só em demo de chat.
- Rodar localmente te dá
privacidade,controleecusto zero. - Você aprende na prática sobre
embeddings,busca vetorial,chunking,retrievaleprompting. - O resultado final é um projeto que já conversa bem com vaga de IA aplicada, automação ou backend inteligente.
O que você vai aprender
Seção intitulada “O que você vai aprender”- Como usar
Ollamapara rodar modelos locais - Como montar uma pipeline de RAG com
LangChain - Como usar
Chromacomo banco vetorial - Como gerar embeddings com
nomic-embed-text - Como subir uma interface simples e elegante com
Gradio - Como ligar tudo isso em uma aplicação que faz sentido fora do tutorial
Pré-requisitos
Seção intitulada “Pré-requisitos”Python 3.10+Ollamainstalado emollama.com- pelo menos
8 GB de RAMlivres, idealmente16 GB - um ou mais PDFs para testar
1. Baixe os modelos no Ollama
Seção intitulada “1. Baixe os modelos no Ollama”Depois de instalar o Ollama, abra o terminal e rode:
ollama pull nomic-embed-textollama pull llama3.2Normalmente isso leva poucos minutos.
Se a sua máquina aguentar bem, vale testar depois
qwen2.5:7b, que costuma se sair melhor em PT-BR.
2. Crie a estrutura do projeto
Seção intitulada “2. Crie a estrutura do projeto”mkdir rag-local-pdfcd rag-local-pdfmkdir pdfsDepois disso, coloque seus arquivos dentro da pasta pdfs.
3. Crie o ambiente virtual
Seção intitulada “3. Crie o ambiente virtual”python -m venv venv
# Windowsvenv\Scripts\activate
# Mac/Linuxsource venv/bin/activateSe tudo deu certo, você vai ver algo assim no terminal:
(venv) PS C:\Projetos\rag-local-pdf>4. Instale as dependências
Seção intitulada “4. Instale as dependências”pip install langchain langchain-community langchain-ollama langchain-chroma pypdf gradioEsse passo pode levar alguns minutos, porque tem bastante coisa para baixar.
5. Crie o arquivo app.py
Seção intitulada “5. Crie o arquivo app.py”Salve este código como app.py:
import os
import gradio as grfrom langchain_chroma import Chromafrom langchain_community.document_loaders import PyPDFDirectoryLoaderfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthroughfrom langchain_ollama import ChatOllama, OllamaEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitter
PERSIST_DIR = "./chroma_db"PDF_FOLDER = "./pdfs"
embeddings = OllamaEmbeddings(model="nomic-embed-text")llm = ChatOllama(model="llama3.2", temperature=0.3)
prompt_template = """Você é um assistente útil e preciso.Responda APENAS com base no contexto abaixo. Se não souber, diga "Não tenho informação suficiente".
Contexto:{context}
Pergunta: {question}
Resposta:"""
prompt = ChatPromptTemplate.from_template(prompt_template)
if not os.path.exists(PERSIST_DIR) or len(os.listdir(PDF_FOLDER)) > 0: print("Indexando PDFs pela primeira vez...") loader = PyPDFDirectoryLoader(PDF_FOLDER) docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=100) splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents( documents=splits, embedding=embeddings, persist_directory=PERSIST_DIR, ) print(f"{len(splits)} chunks indexados!")else: vectorstore = Chroma( persist_directory=PERSIST_DIR, embedding_function=embeddings, ) print("Banco vetorial já existe.")
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)
rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
def chat(message, history): response = rag_chain.invoke(message) return response
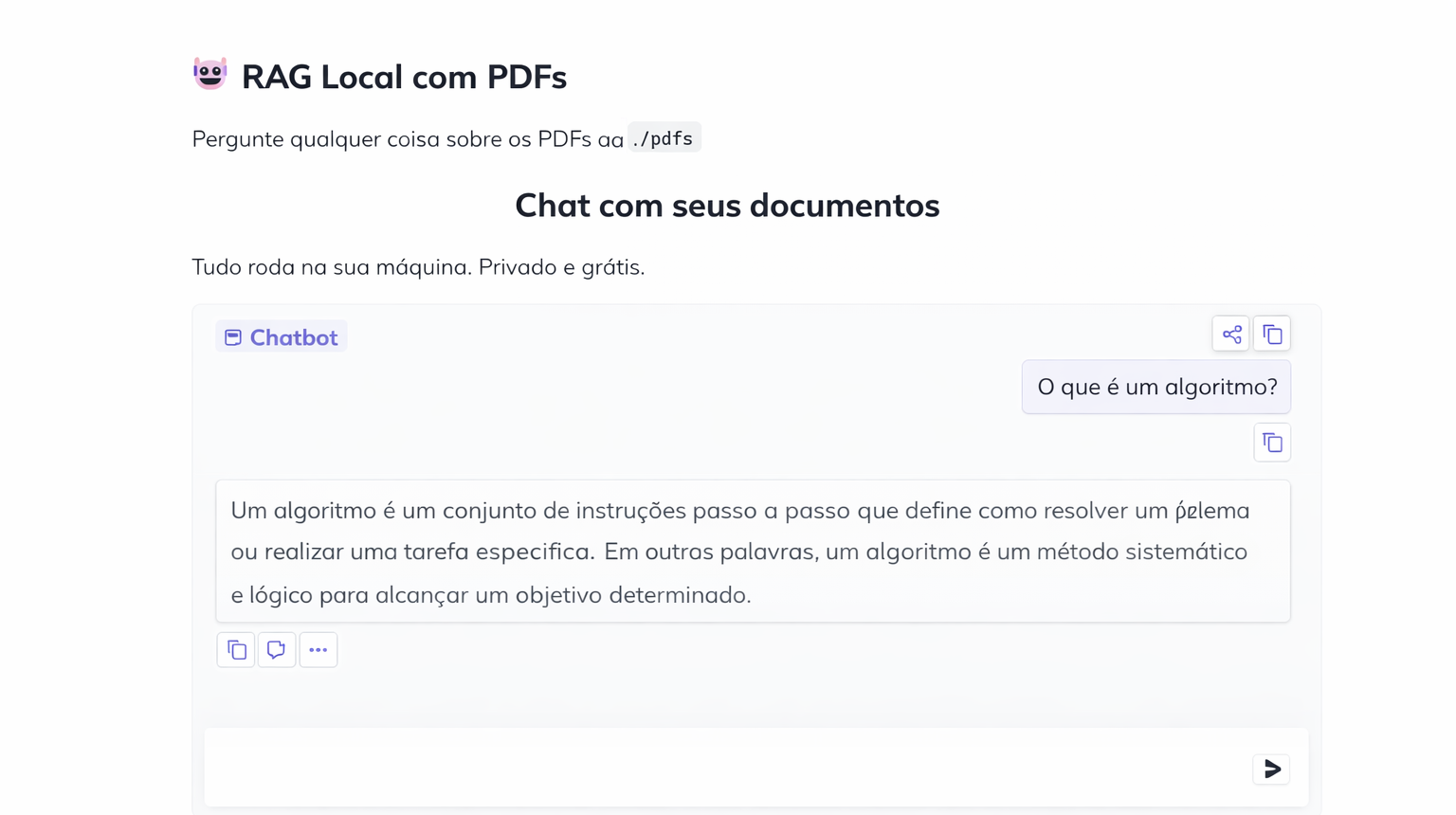
with gr.Blocks( title="Minha IA Local - Chat com PDFs", theme=gr.themes.Soft(),) as demo: gr.Markdown( "# RAG Local com PDFs\nPergunte qualquer coisa sobre os PDFs da pasta `./pdfs`" )
gr.ChatInterface( fn=chat, title="Chat com seus documentos", description="Tudo roda na sua máquina. Privado e grátis.", examples=[ "Qual é o principal ponto do documento?", "Resuma o texto em 3 frases", "O que diz sobre [tópico do seu PDF]?", ], )
if __name__ == "__main__": demo.launch(share=False)6. Rode o projeto
Seção intitulada “6. Rode o projeto”python app.pyNa primeira execução ele vai carregar e indexar todos os PDFs da pasta. Dependendo do tamanho dos arquivos, isso pode demorar alguns minutos e consumir bastante CPU e memória.
Se o uso de recurso subir forte, está tudo dentro do esperado.
7. Teste seu RAG na prática
Seção intitulada “7. Teste seu RAG na prática”Quando a indexação terminar, abra o link exibido no terminal. Em geral ele vem assim:
http://127.0.0.1:7860Isso vai abrir no navegador uma interface bem amigável, com cara de chat moderno, só que rodando na sua máquina.
Daí em diante é simples: faça perguntas sobre o conteúdo dos PDFs e veja o modelo responder com base no contexto recuperado.
O tempo de resposta depende bastante do seu hardware. Vai ser mais lento do que uma LLM paga na nuvem, mas em troca você ganha privacidade, previsibilidade de custo e um entendimento muito mais concreto da arquitetura.
O que está acontecendo por trás
Seção intitulada “O que está acontecendo por trás”Em alto nível, o fluxo é este:
- Os PDFs são carregados
- O texto é quebrado em
chunks - Cada chunk vira embedding
- Os embeddings vão para o
Chroma - Quando você faz uma pergunta, o sistema recupera os trechos mais relevantes
- O modelo responde usando esse contexto
Esse é o coração de quase toda aplicação séria de RAG.
Próximos upgrades que valem a pena
Seção intitulada “Próximos upgrades que valem a pena”Depois que isso estiver funcionando, você pode evoluir o projeto com:
- upload de PDF pela interface
- memória de conversa
- citações com fonte e página
- suporte a múltiplas coleções
- troca de modelo para comparação de desempenho
- persistência mais refinada do índice
Se você queria um projeto direto ao ponto para estudar IA aplicada sem depender de API paga, esse é um dos melhores para começar com o pé direito.
E, quando você abre o projeto no navegador, a interface fica assim: